Dataset
챗봇과 대화를 진행할 때 이전 대화 내용에 대한 정보를 주지 않고 새로운 메세지만을 전달한다면, 챗봇은 처음 받는 질문으로 판단하고 대답하게 됩니다.
따라서 이전 대화 내용을 프롬프트에 함께 전달하여 일관성있는 답변을 생성할 수 있도록 만들어야 하죠.
하지만 모든 대화 원문을 저장하는 것은 많은 토큰을 필요로할 것입니다.
따라서 대화의 길이를 줄이면서 그 내용은 유지하기 위해 대화 내용을 요약하는 과정이 필요합니다.
Langchain Memory
기본적으로 대화 내용을
Langchain의 Memory 기능과 비슷하게 제작하려고 합니다.
아래 대화를 Langchain의 ConversationSummaryBufferMemory를 활용하면 다음과 같이 저장하게 됩니다.1
한 턴마다 대화를 요약하여 String 형태로 저장이됩니다.
재미있는 부분은 마지막 대화에 대해서는 요약을 진행하지 않는 것입니다.
대화를 계속 이어 나가보겠습니다.
1
대화를 진행하다 보니 앞서 저장되었던 대화의 일부가 요약된 것을 볼 수 있습니다.
마지막 대화 역시 너무 길다보면 토큰을 줄이기 위해 요약될 수 있다고도 합니다.
Dataset
질문자의 질문과 참고 문헌을 통한 응답을 생성하는
AIHUB 지식검색 대화
 를 기반으로 데이터셋을 구성하였습니다.
를 기반으로 데이터셋을 구성하였습니다.
를 기반으로 데이터셋을 구성하였습니다.요약
대화를 요약하는 모델을 학습하기 위해 아래와 같은 형식의 데이터셋을 구축해야합니다.
1
현재
Gemini는 분당 60회의 API 요청이 무료로 사용이 가능합니다.
따라서 지식검색 대화 데이터셋에서 오고 간 질문과 응답을 Gemini를 활용하여 요약한 데이터를 생성하려 합니다.
Few-Shot을 통해 우리가 하려는 작업이 요약임을 예시를 통해 보여주고, 생성하려는 데이터의 입력을 넣어 나오는 출력을 학습하기 위한 데이터셋으로 형성하려고 합니다.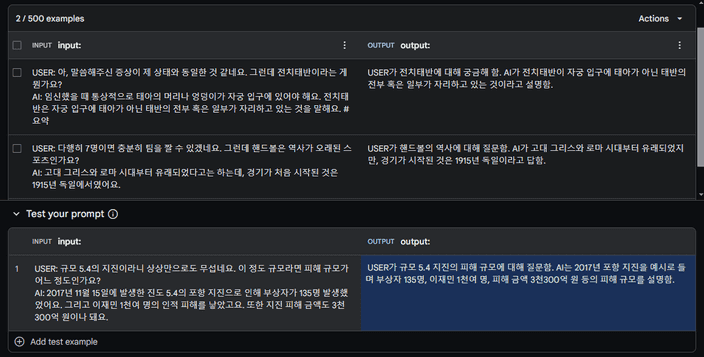
기본적으로 두 개의 예시를 입력하고 추론을 진행하였을 때 적절한 결과를 보여준다는 것을 알았습니다.
하지만 각 대화당 약 10번의 턴이 존재하는데, 매번 한번에 한 턴씩 데이터를 생성하는 것은 너무 오랜 시간이 걸릴 것 같아요.
따라서 여러 입력을 처리할 수 있도록 변경해야 할 것 같습니다.
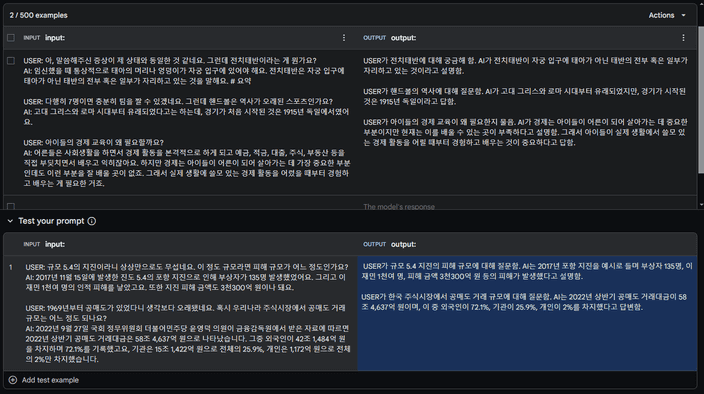
이러한 방식으로 여러 작업을 한꺼번에 처리할 수 있을 것 같습니다.
하지만 너무 많은 턴의 대화를 입력으로 넣어주다 보면 AI가 판단하기에 필요하지 않은 턴은 요약을 생략하고 생성하더라구요.
따라서 적절한 크기의 입력을 조절하는 것이 필요했습니다.
1
QnA
응답을 생성할 때 프롬프트에 함께 함께 넣어줄 정보에서 필요한 부분만을 이용하는 강건한 모델을 만들기 위해
RAFT
방법을 적용해 데이터 형식으로 응답에 필요한 정보 1개와 상관없는 정보 2개를 임의의 순서로 Context를 구성하였습니다.
또한 위 방법에서 요약한 대화를 History로 함께 넣어주어 요청과 문맥을 모두 고려하여 대답을 생성하도록 만들었죠.
RAFT에서 Chain of Thought를 활용하면 응답의 품질이 높아진다고 주장하였습니다.
이를 활용하기 위해 응답 생성시 제시된 정보 중 정확히 어떠한 문구를 사용했는지 전달하기 위해 Reference 데이터도 함께 생성하도록 구성하였습니다.1