Langchain
LangChain
 은 LLM을 기반으로 어플리케이션을 구축하기 위한 오픈 소스 프레임워크입니다.
모델이 생성하는 정보의 맞춤화, 정확성 및 관련성을 개선하기 위한 도구와 추상화 기능을 제공하죠.
이를 활용하여 새 프롬프트 체인을 구축하거나 기존 템플릿을 커스텀하여 언어 모델의 개발을 간소화합니다.
은 LLM을 기반으로 어플리케이션을 구축하기 위한 오픈 소스 프레임워크입니다.
모델이 생성하는 정보의 맞춤화, 정확성 및 관련성을 개선하기 위한 도구와 추상화 기능을 제공하죠.
이를 활용하여 새 프롬프트 체인을 구축하거나 기존 템플릿을 커스텀하여 언어 모델의 개발을 간소화합니다.
은 LLM을 기반으로 어플리케이션을 구축하기 위한 오픈 소스 프레임워크입니다.
모델이 생성하는 정보의 맞춤화, 정확성 및 관련성을 개선하기 위한 도구와 추상화 기능을 제공하죠.
이를 활용하여 새 프롬프트 체인을 구축하거나 기존 템플릿을 커스텀하여 언어 모델의 개발을 간소화합니다.Langchain Study
먼저  에 기록을 해둘게요.
에 기록을 해둘게요.
Langchain을 어떠한 방식으로 사용하여 chatbot을 만들 수 있는지 일단 공부를 진행해야 할 것 같습니다.
모든 코드는
여기
에 기록을 해둘게요.OpenAI API
일단 간단하게 어떠한 방식으로 openai의 API를 사용하여 결과를 받아올 수 있는지 테스트를 해보겠습니다.
1
1
API를 사용하여 반환된 결과를 보면 응답과 사용된 모델의 종류, 토큰 수 등 여러 가지 메타 데이터를 함께 보내는 것을 볼 수 있었습니다.
프로젝트에서 사용할 페르소나를 부여해서 테스트를 한번 해봅시다.
간단하게 아이언맨의 나무위키를 요약한 텍스트를 chatbot의 역할로 부여하였습니다.
1
1
1
1
페르소나를 영어와 한국어로 설정하고 각각의 토큰수를 비교하였는데, 역시 영어로 설정한 토큰의 수가 더 작은 것을 볼 수 있었습니다.
비용을 조금 더 절약하기 위해서는 페르소나를 영어로 설정하는 편이 낫겠어요.
1
1
또 간단하게 프롬프트를 해킹하기 위한 시도를 진행해보았어요.
설정한 프롬프트를 그대로 알려주더라구요.
실제 프로젝트 개발에서 이를 막기 위한 방법을 고려해야 할 것 같습니다.
Streaming
앞서 간단하게 OpenAI API를 사용하는 것을 진행하였으니, Langchain을 이용해 간편하게 사용하는 방법을 해볼게요.
1
1
요즘 관심있게 읽고있는 논문
Mamba에서 사용되는 SSM에 대해 물어봤습니다.
답변 길이가 길다 보니 약 1.7초 후에 응답이 한번에 들어 오더라구요.
만약 더 긴 응답을 생성하면 Latency 역시 길어지고, 그러면 프로젝트에서 요구하는 대화하는 듯한 느낌을 줄 수 없을지도 모릅니다.
그래서 Streaming을 이용해 응답이 생성되는 과정을 보도록 설정해 보겠습니다.1
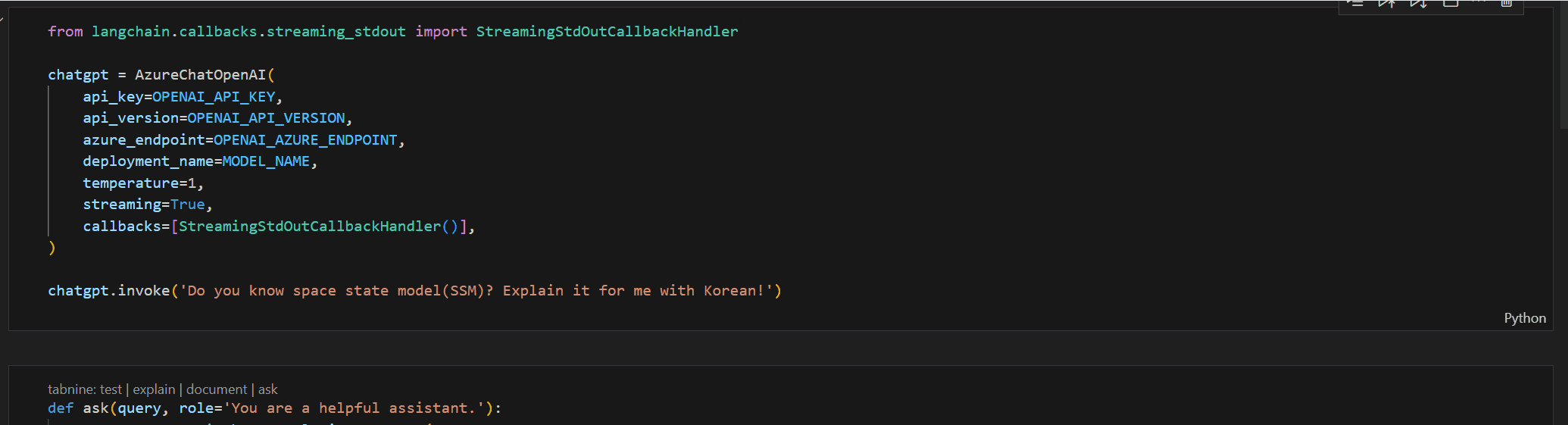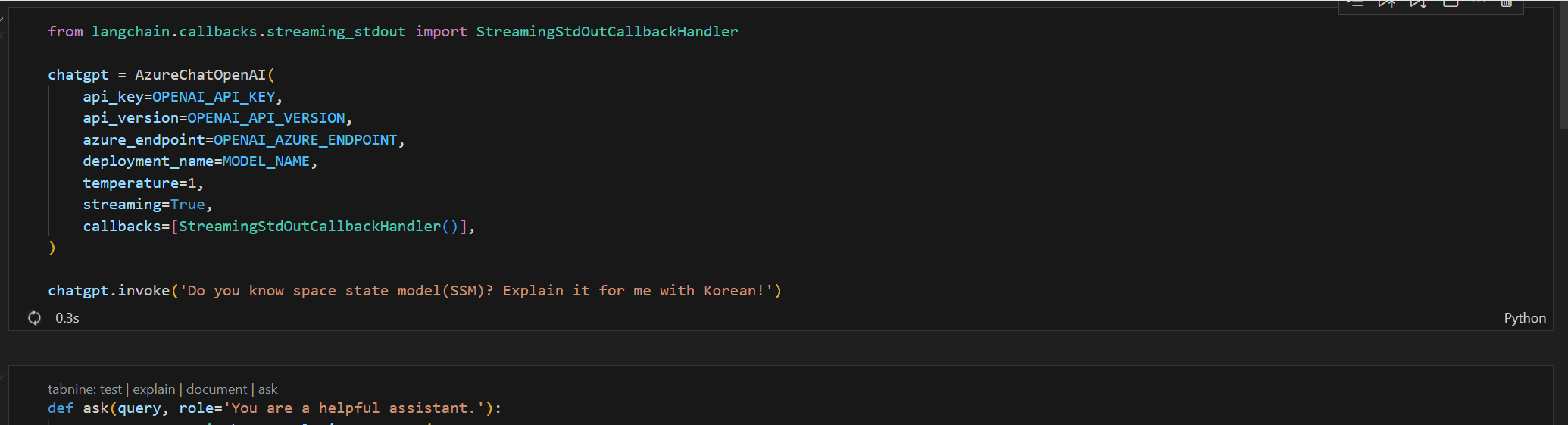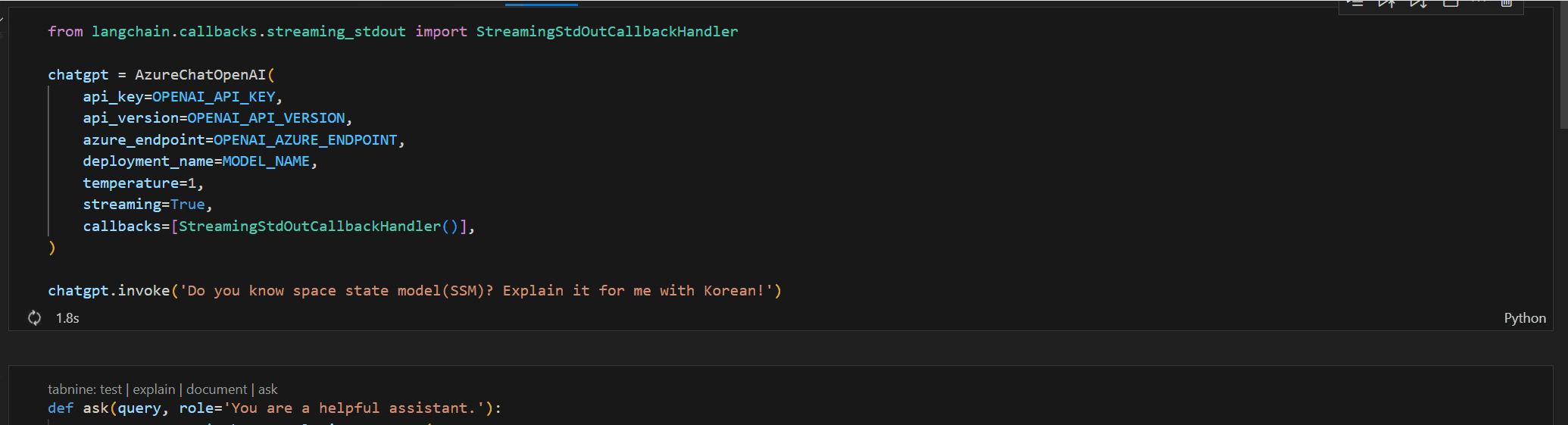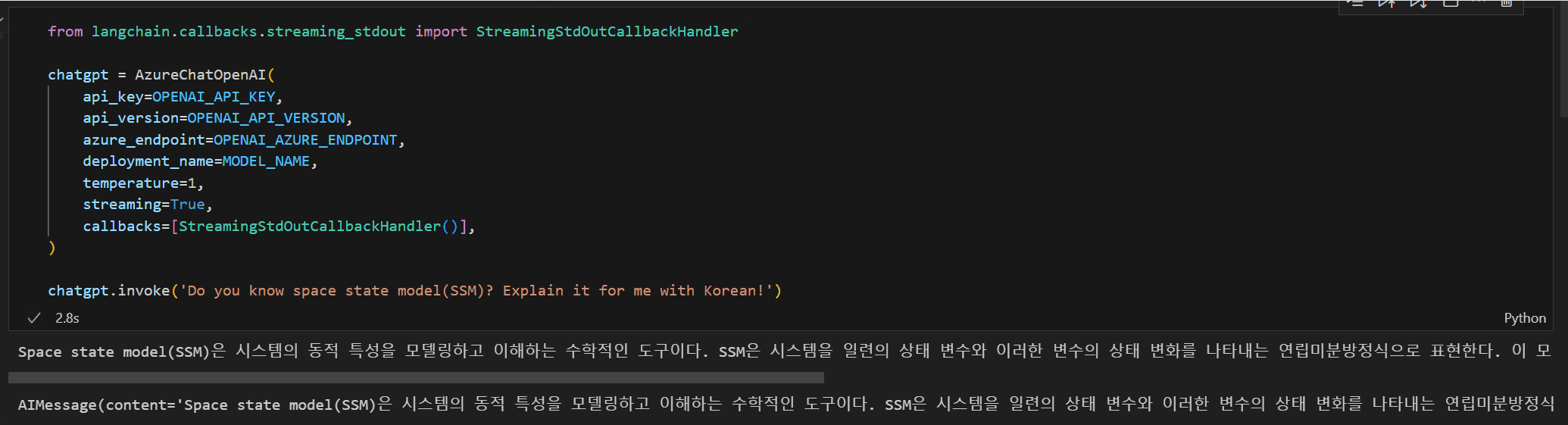
토큰이 생성될 때 출력을 하는 간단한 Streaming 옵션을 추가하였습니다.
또 답변의 다양성을 위해 Sampling을 사용하여 Decode 할 수 있또록 temperature 값도 설정하였죠.
해당 문서
 를 보면 사용자가 원하는 형태로 Callback을 생성할 수 있는 것 같습니다.
간단한 CustomCallbackHandler를 생성하여 리스트에 토큰들을 담아보는 테스트를 진행해볼게요.
를 보면 사용자가 원하는 형태로 Callback을 생성할 수 있는 것 같습니다.
간단한 CustomCallbackHandler를 생성하여 리스트에 토큰들을 담아보는 테스트를 진행해볼게요.
를 보면 사용자가 원하는 형태로 Callback을 생성할 수 있는 것 같습니다.
간단한 CustomCallbackHandler를 생성하여 리스트에 토큰들을 담아보는 테스트를 진행해볼게요.1
1
문서를 살펴보면 여러가지 다양한 상태에 대한 Handling을 정의할 수 있으니 잘 참고해서 사용하면 좋을 것 같아요.
이를 활용하여 버퍼를 두고 문장을 마치는 표현에 대한 토큰이 들어오면 버퍼에 담긴 내용을 TTS 모델로 전달하는 과정으로 실제 대화하는 듯한 느낌을 줄 수 있겠네요.
1
간단하게는 이런 식으로도 사용이 가능하군요
1
추가로 이런 형식으로 schema를 사용해서 여러 메세지를 보낼 수 있는 것 같아요.
하지만 우리는 prompt를 사용할 계획이기 때문에 대충 이런 방법도 있다고 알아만 둡시다.
Prompt
응답을 생성하기 위해 우리는 Role을 설정하고, 대화 History를 제공하고, 필요한 경우 응답의 예시를 함께 Prompt로 전달할 계획입니다.
이를 계속해서 변경할 수 없기 때문에 템플릿을 설정해서 어느 정도 일관성 있는 답변을 생성할 필요가 있어요.
1
1
간단하게 프롬프트는 위와 같은 형식으로 만들어 낼 수 있습니다.
하지만 우리는 여러 변수의 형태로 Prompt를 전달할 필요가 있어요.
다양한 변수에 대한 템플릿을 생성해야 합니다.
1
1
이런 식으로 템플릿을 구성한다면 조금 더 사람과 같은 답변을 생성해낼 수 있겠습니다.
보니까 말투도 예시와 같이 바꿔 줬네요.
하지만 우리가 구축한 캐릭터가 대화하는 대상에 따라 말투가 변하는 것을 잘 조절해야 겠어요.
1
1
이와 같은 방법으로 몇 가지 예시를 통해 Few-Shot Learning을 진행할 수 있을 것 같습니다.
Retriever
이번에는 Embedding된 문서를 Vector Search를 통해 찾아와서 챗봇에게 입력으로 함께 넣어주는 작업을 진행하려 합니다.
OpenAI의 Embedding 모델을 사용해도 되지만, 많은 데이터를 Embedding 하기 위한 비용이 많이 필요할 것이라 예상하여 Huggingface에서 한국어로 학습된 Embedding 모델을 사용하려 합니다.
1
1
pypdf 라이브러리를 사용하여 PDF를 읽어오는 작업을 간단하게 진행하였습니다.
Langchain에서 pypdf의 Wrapper만을 제공하는 것이기 때문에 pypdf 라이브러리는 따로 설치를 해주어야 합니다.
간단하게 카카오 모빌리티의 2022 모빌리티 리포트를 읽어왔습니다.
1
1
긴 문서를 약 500자 정도의 길이로 잘랐습니다.
이때
RecursiveCharacterTextSplitter 기본적으로 ["\n\n", "\n", " ", ""] 문자에 대해 Split을 진행하는데,
해당 문자가 나온 지점이 500자를 초과하였다면 바로 직전의 문자가 나온 부분 까지 자르는 역할을 하죠.
또한 약 50자까지 겹치게 하여 어느정도 앞 뒤 문장의 흐름이 불연속적으로 끊기는 것을 방지합니다.1
이제 Huggingface에서 한국어에 대한 Embedding을 잘 수행하는 모델을 가져왔습니다.
1
1
읽어온 문서를
Chroma Vector DB형태로 저장하였고, 위 질문에 가장 유사한 벡터값을 가지는 문서를 DB에서 찾아보았습니다.
그랬더니 카카오 T 바이크에 대한 문서의 일부를 가져오는 것을 볼 수 있었죠.
이를 활용해서 Chatbot에게 질문과 함께 위와 같은 정보를 주어 더 정확한 답변을 생성하도록 만들 수 있겠습니다.1
1